Control Planes for Database-Per-User in Neon
Designing a control plane to scale your multi-tenant app

Due to its serverless architecture, Neon is a great option for building multi-tenant, database-per-user applications in Postgres. In a previous post, we explored the various approaches to multi-tenancy in Postgres, with a particular focus on the database-per-user architecture and its advantages for isolating customer data.
In this second post, we dive into a crucial component of managing database-per-user systems: the control plane. Understanding and implementing an effective control plane is key to scaling your application while maintaining operational efficiency and security.
The Neon object hierarchy
Before we get into the specifics of control planes, let’s review the core concepts that make up the Neon ecosystem so that you can follow through the logic of the sections below.
Neon is a Postgres service with a custom-built storage engine that separates compute from persistence. When you build on Neon, you organize your backend in a hierarchy of three primary elements: projects, branches, and databases.
- A project in Neon acts as a container for all your database resources. Each project can host multiple branches and databases, making projects the top-level unit within your Neon organization.
- Branches in Neon are similar to branches in version control systems like Git. They allow you to create copies of your database environment at specific points in time and make changes in an isolated sandbox. This feature is particularly useful for testing, development, or experimenting with new features without affecting the main branch.
- Within each branch, you can have one or more Postgres databases. These databases store the actual data and are isolated from each other, even within the same branch.
When talking about database-per-user architectures in Neon, we’re usually speaking of a project-per-user design. Projects offer the highest level of isolation, and features like branching and PITR are difficult if not impossible to use safely without each user’s data in its own project.
If you’re creating one Neon project per user, the number of Neon projects will quickly grow. Managing them individually becomes increasingly complex and time-consuming — so a centralized approach will be necessary to stay on top of operations. This is where the control plane comes into play.
What does a control plane look like?
The term “control plane” originated in network administration, describing routing rules over a “data plane” of packet traffic. More recently, it’s been generalized to mean systems that facilitate other systems’ management.
The Neon console and tools like `neonctl` are themselves part of a control plane. Diving into those yourself is an important first step in learning how Neon works and getting your systems off the ground, but building a more centralized solution will be a critical part of scaling your database-per-user architecture.
In this article, we’re going to discuss the control plane as a basically singular software system—but it’s a much fuzzier concept than might immediately be evident. The control plane extends not just to tools you build to manage your application, but to other systems entirely, from CI/CD to observability platforms to schema migration frameworks. Nor does this meta-system stop at software: your first steps into the control plane will tend to look more like standard operating procedures and runbooks.
The control plane also grows with your system and your organization. You’ll likely start by supplementing the general-purpose capabilities of the Neon console and neonctl with individual specialized tools — shell scripts, spreadsheets, little glue programs, admin modes or modules. These automations help ensure that routine tasks don’t become major timesinks. But in the long run, it’s hard to standardize these many discrete moving parts, which is solved by building a consolidated, consistent management platform.
Disclaimer: You probably shouldn’t invest a lot of time into organizing control plane software before you have customers. Exceptions exist, but it’s important to engineer for the problems you’re actually facing. In most cases, runbooks and elbow grease will get your first deployments out as effectively. Evolving past that tends to be part of the chasm-crossing effort, in Geoffrey Moore’s classic formulation: automation and standardization are how you scale your distribution channel to be able to serve more and more customers.
The catalog database
At its core, the catalog database is a special database that serves as a centralized hub for tracking and managing all your Neon projects and databases. This should be its own self-contained Neon project, ensuring it is isolated from user data and user-facing systems.
The Neon console provides a standard set of metadata for each project—details like project age, active branches, and compute sizes. But this built-in functionality may not be sufficient for more specific operational needs, such as tracking the current deployed schema version or monitoring customer billing status. Centralizing this critical but more specialized information in the catalog database is the first step toward effectively managing your projects at scale.
The first and most important component of the catalog database is a manifest of users (or accounts, or however you name them in your system). This manifest is essentially a list of all your customers or organizational units for whom you provision Neon projects. From this starting point, you can build out the catalog database to include your other metadata:

Advice for designing your catalog database schema
- Linking tables like
projectandpaymentto theaccounttable using foreign keys helps maintain data integrity and ensures that each project or payment is correctly associated with an account. - Use data types like
citextfor case-insensitive text fields,uuidfor unique identifiers to avoid surfacing information about your sequences, andtimestamptzfor anything to do with tracking concrete, real-world time. - Capture critical operational data, such as
schema_version, in theprojecttable. This information will be essential for managing updates and ensuring consistency across your Neon projects. - Don’t forget about indexing! While the catalog is and will likely remain much smaller than all but the emptiest per-user database it manages, it will grow, especially if you’re tracking repeated events like payments. You’ll be spending a fair amount of time in the control plane – it’s important that it continues to perform well as you scale.
- While it’s tempting to include every possible piece of data, start with the essentials and plan for extensions as your needs evolve.
- Standard Neon metadata like compute size or branch information are already available in the console. You most likely don’t need to replicate this information in the catalog database as well, unless having to look it up separately is becoming a significant time sink or adding a lot of complexity to management workflows.
Entering the control plane
The control plane has many uses, but among the earliest and most important is getting new customers onboarded to your system. In a database-per-user setting, this means standing up a new Neon project at minimum, but it can mean many other things as well:
- Billing and invoicing
- Updating the catalog database with the new Neon project information
- Storing some initial information in their database: the organization name, the registering email address so the first user can provision others, and so on
- In isolated environments, provisioning a new application instance
- Notifying customers that the activation process is complete
When you’re just starting your automation journey, the control plane probably won’t do all of this, or even necessarily most of it. If your target clients are fewer and bigger, onboarding could even be rare enough that you might find it a better use of effort to concentrate on other control plane functions entirely.
But if you find you’re spending a lot of time and effort on onboarding — or anything else — and begin taking steps to automate it, that’s a control plane. It might be some horror story of an undocumented, uncontrolled shell script on a founding engineer’s laptop that reads a CSV emailed manually when someone signs up, but there are good control planes and bad control planes.
Good control planes are systematically thought out, provide clear and unambiguous information and capabilities, and are accessible to anyone who needs them (and only to those people). Bad control planes grow organically as emergencies come up but are never reorganized with a holistic sense for what both the organization and its engineers need. They are unclear, unreliable, present information partially or inconsistently. Often, only one person understands them or is allowed to operate them, although this isn’t an infallible sign at smaller organizations.
Control planes, control towers
Monitoring and observability is a big space in the 2020s. When developing on Neon, basic metrics will split between the Neon console and whatever observability platform you deploy or integrate into your application. Both these tools are part of your control plane in that fuzzier meta-system sense. So why, and for what, should you consider adding monitoring capabilities to your control plane in the specific sense? What third type of operational information can’t the other two options surface easily?
There’s a whole class of useful data which neither the console nor traditional monitoring or observability software makes visible: the sorts of things someone asks, “can we run a query to see _____?”. There’s any number of ways to fill in that blank. If you sell features, support tiers, or anything else à la carte; if counts, frequencies, and other point-in-time aggregates need to be reported; if you have all-Postgres background processes that can’t easily push metrics to an integrated provider: the dedicated control plane is the obvious place to make this kind of information visible.
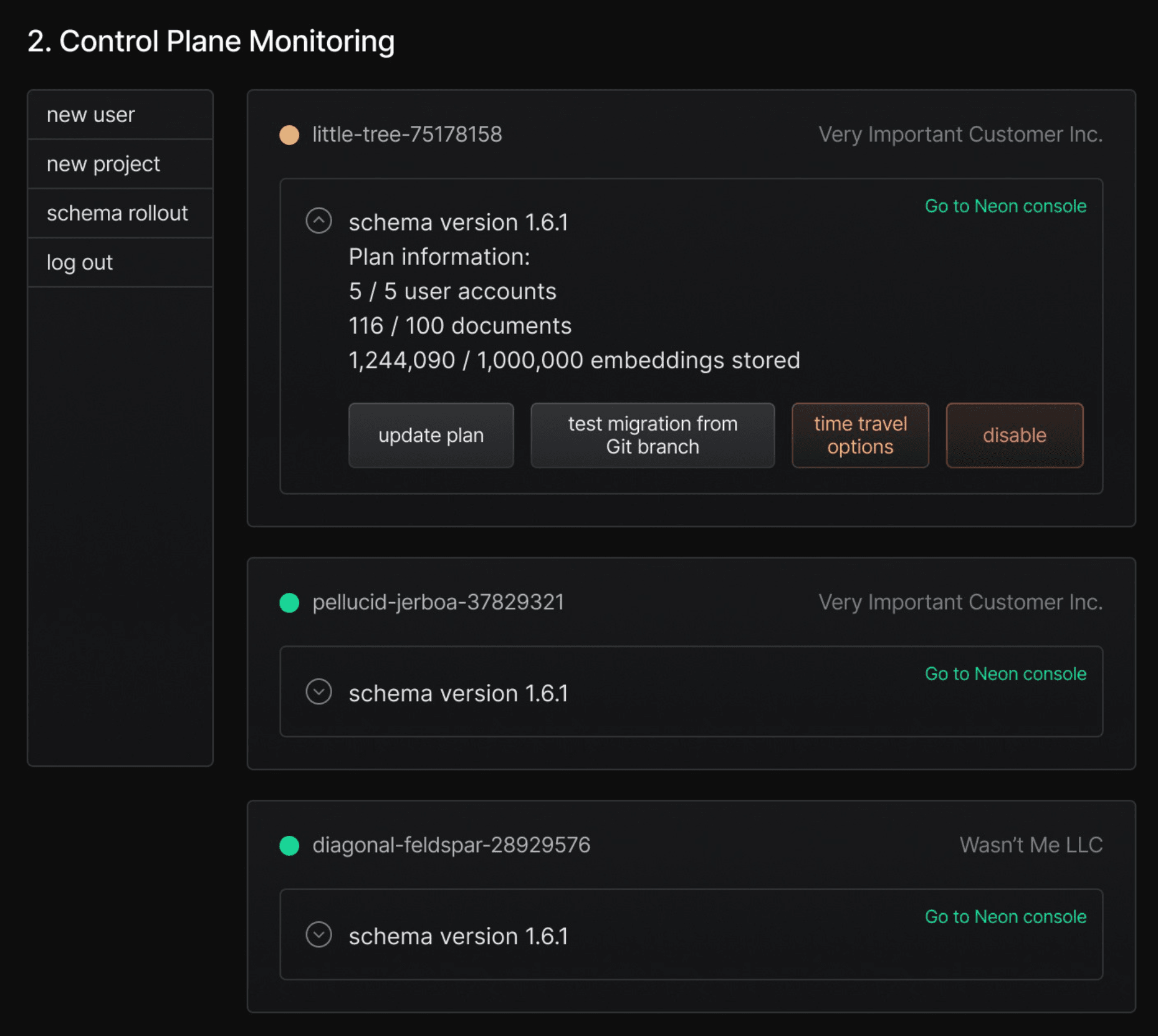
Control plane data are most easily queried from the catalog database. It’s absolutely possible to look up information in each per-user database — that’s how a shared application environment approach works in the first place — but it’s a lot simpler to make one query for all projects than it is to make one query per project. A central data repository also makes it possible to connect a dashboarding or business intelligence system to your control plane.
Of course some data, such as in-database process performance metrics, are resolutely local. And in fully isolated application environments, you’ll need to have information like feature enablement stored in-project so the application instance can use it. However, ease of surfacing information from the catalog database compared with local dbs is only one factor exerting pressure toward centralized data architecture. We’ll get into some others when we discuss the shared and isolated instance strategies.
Life on the control plane
Day-to-day control plane operations, such as maintenance, troubleshooting, and recovery, tend to happen to databases individually and at different times or cadences. This means the console and `neonctl` are likely able to fulfill many of your needs for longer even as you scale, compared to something like the immediate and specialized requirements of onboarding.
However, if you make extensive or routine use of some of Neon’s more powerful features, turning common tasks into push-button operations can make them substantially faster and safer. Managing logical replication, for example, involves several steps in both the source and destination, and getting an argument wrong or missing a setting can be difficult and frustrating to debug.
And there’s one big part of maintenance that it’s crucial to centralize sooner rather than later. Software changes; so do database schemata. At some point, you’re going to have to roll out an upgrade. Schema upgrades, or migrations, are never trivial even for a single database. When each user has their own Neon project, it becomes not just a problem of correctness but of synchronization, especially in a shared application environment. We’ll discuss the implications and tactics for managing migrations in future posts, but the control plane has an important general role to play here.
One of the most important things the control plane can tell you, full stop, is the deployed schema version for each and every per-user database. It’s critical to use a migration framework such as sqitch, graphile-migrate, Flyway, or whatever built-in migration support is supplied by your web framework or data access layer of choice; every one of these worth its salt has an in-database version registry your control plane can query. Many also support a “baseline” operation that converts an existing schema to an initial migration script.
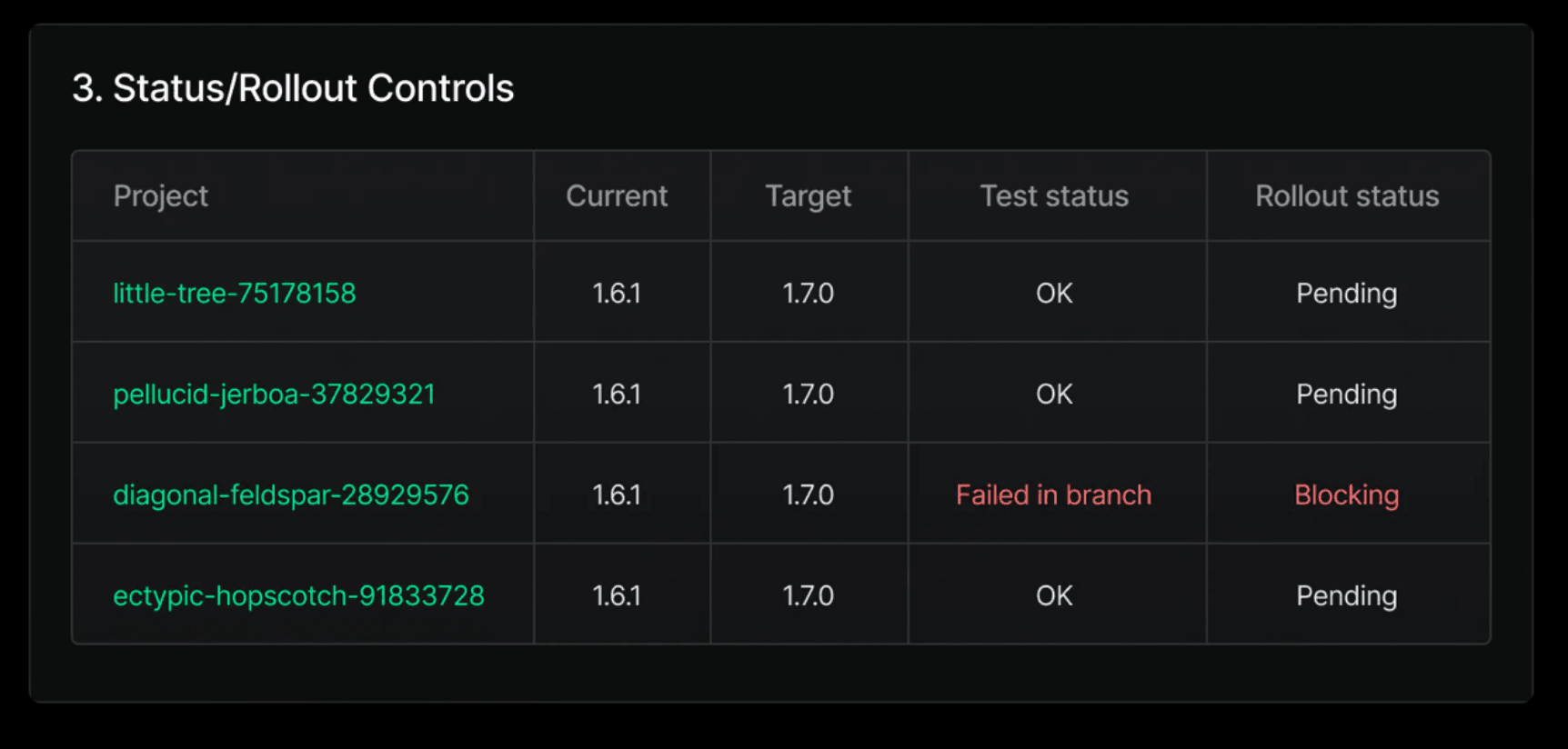
When you know which schema version is deployed to a database, the next logical step is to do something with that information. Triggering and monitoring the progress of upgrade rollouts is as if not more important than onboarding: you usually onboard each customer a maximum of one time, but upgrades happen forever after.
Key takeaways: Designing an effective control plane
As we’ve explored, building and managing a database-per-user architecture requires a strategic approach to control plane design. The details depend on your organization’s data and deployment needs, on your choice to deploy a single shared or many isolated environments, and on the engineering effort you’re able to invest into getting ahead of scale. No two implementations are exactly alike. However, there are still a few general governing principles:
- Start simple, scale thoughtfully. The Neon console and tools like
neonctlwill help you get off the ground, but as your system grows and the number of your Neon projects increases, you’ll need more. Prioritize automation for tasks that consume the most time and effort, like onboarding or schema migrations. - The control plane is an internal product. Treat it like one: understand who needs it, who uses it, who should use it and isn’t, and the why and how of each. Cultivate its growth. Take a conscious approach to design and avoid growing the control plane reactively in a “fire-fighting” mode.
- Centralize your metadata. By centralizing vital metadata—like user manifests, billing, and per-project operational data—you can streamline your own operations and reduce the complexity of managing multiple projects.
- Pick your battles wisely. Spending a lot of time on your control plane before you have projects to manage is almost always a bad bet. Be sure you have a problem before you start solving it, and gradually build a more centralized and consistent management platform as your needs evolve.
- Use the catalog database for insights. When managing multiple projects, it’s more efficient to query a central catalog database rather than accessing each per-user database individually. This centralization allows you to monitor, maintain, and upgrade your entire system more effectively, supporting your ability to scale.
So: What does your control plane look like?
The one thing all control planes have in common is that they integrate and standardize operations on the data plane. They render it legible, in the sense James C. Scott uses the term to imply “a viewer whose place is central and whose vision is synoptic”, that is, comprehensive and summarizing.
Individual views of and individual actions on individual databases under management are difficult to trace, to reason about, and to perform consistently and safely, especially as your customer base grows. More than an application, the control plane is a strategy for centralizing governance of your data resources and minimizing the risks of technical operations, by channeling actions through a consistent set of abstractions and procedures.