If I have read-only tables in Postgres, should I index them heavily?
Like many good database questions, the answer is: it depends
We often get questions about Postgres indexing strategies, and read-only (or read-heavy) tables are especially interesting. This post was actually inspired by this question on Reddit:
“I have a table with about 20 columns that each have Boolean values indicating whether the row has a specific characteristic. This is a fairly small table (8k rows) that is rarely updated or deleted, and those changes are only made by an admin. The table is used on a search page for my site to return results. Should I index every searchable column to optimize its performance?”
What the user is asking here is: should all columns in a relatively small, read-only table be indexed to maximize search performance? Given that the table is rarely updated and serves a critical role in a search function, it might seem intuitive to heavily index all searchable columns.
But as it so often happens with Postgres indexing, the reality is more nuanced. In this post, we’ll reflect on the factors influencing indexing decisions for read-only tables.
A quick primer: What’s read-only, what’s indexing, and what’s “heavily”?
Let’s start with indexing, as that’s what we’re talking about. In Postgres, indexing is a database optimization technique that creates a copy of selected columns of data from a table, organized such that Postgres engine is able to find specific rows quickly without the overhead of scanning the entire table.
Now, what’s heavy indexing vs. light indexing? Say we have a table that looks like this:
CREATE TABLE IF NOT EXISTS products (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
category VARCHAR(50),
price DECIMAL(10, 2),
stock_quantity INTEGER,
manufacturer VARCHAR(100),
created_at TIMESTAMP
)
A “light” index might have single-column indexes or only indexed the most critical columns. In the above table, we might create an index for:
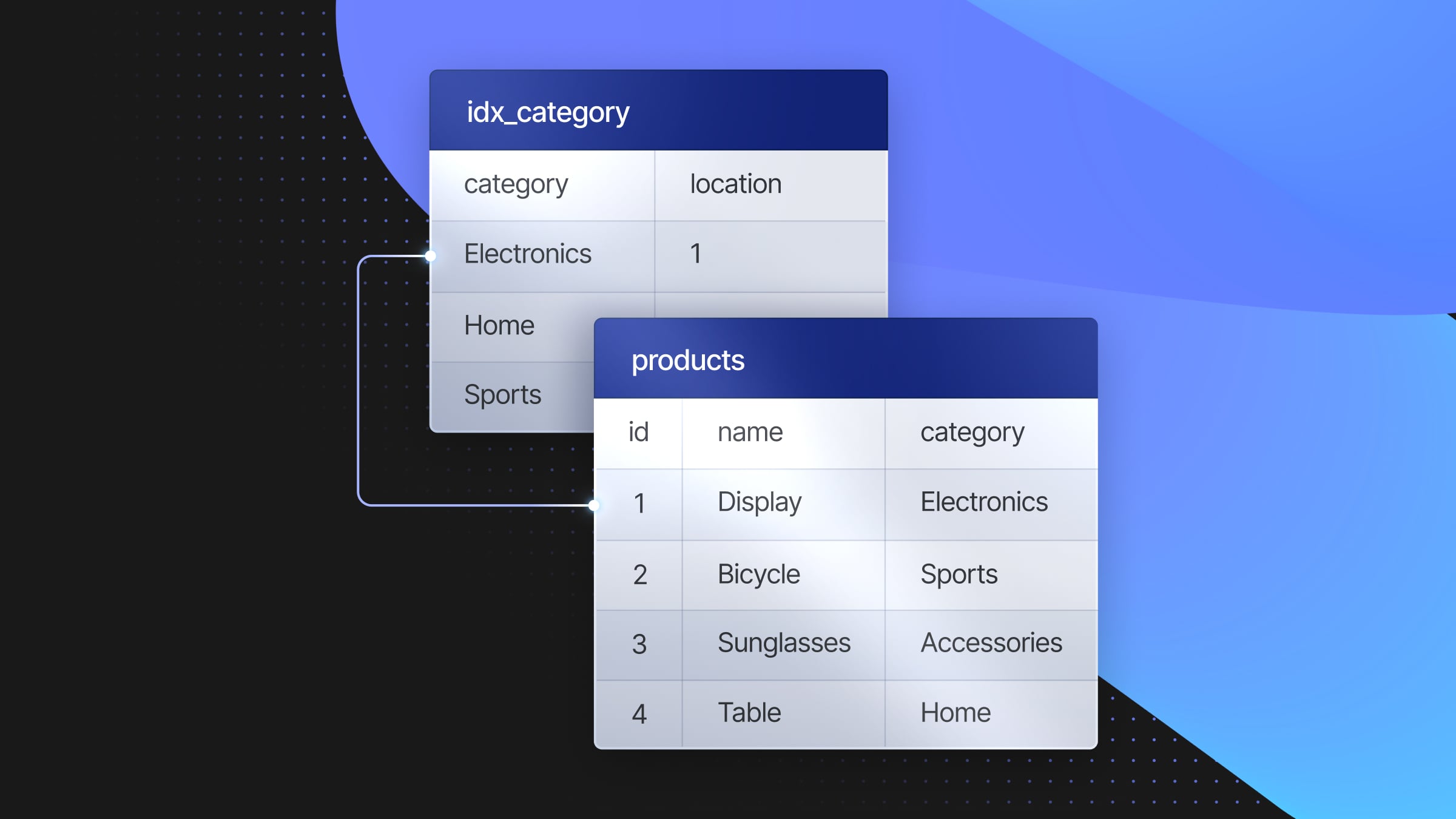
CREATE INDEX idx_category ON products(category);
CREATE INDEX idx_price ON products(price);A “heavy” index might include multi-column indexes, covering/composite indexes, and specialized index types.
The indexes on the above table might look like this:
CREATE INDEX idx_category_price ON products(category, price);
CREATE INDEX idx_price_category ON products(price, category);
CREATE INDEX idx_manufacturer ON products(manufacturer);
CREATE INDEX idx_created_at ON products(created_at);
CREATE INDEX idx_price_created_at ON products(price, created_at);
CREATE INDEX idx_category_price_stock ON products(category, price, stock_quantity);
CREATE INDEX idx_category_price_included
ON products(category, price)
INCLUDE (name, manufacturer); -- Covering indexThe complexity of query patterns primarily drives heavy vs. light indexing. In a light indexing scenario, you might have a small set of frequently executed queries that access data through simple predicates, typically involving equality comparisons on single columns (e.g., WHERE category = 'Electronics').
As query patterns become more complex, heavy indexing becomes more beneficial. Complex patterns might include:
- Range queries (
WHERE price BETWEEN 100 AND 500) - Multi-column filtering (
WHERE category = 'Electronics' AND price > 1000) - Sorting on multiple columns (
ORDER BY manufacturer, price DESC) - Queries with multiple
JOINconditions
In these cases, composite indexes that cover multiple columns in a specific order can be used.
Finally, what does read-only have to do with indexing? In a typical Postgres database, you’re constantly juggling between optimizing for quick reads (queries) and efficient writes (inserts, updates, deletes). Every index you add makes reads faster, but slows down writes because the database needs to update the index for every write.
With read-only tables, you’ve taken writes out of the equation. Theoretically, you can go nuts with your indexes without worrying about write performance. You can create those complex, multi-column indexes, add covering indexes that include all the data needed for specific queries, or even use specialized index types like BRIN or GIN indexes that would be too costly to maintain in a write-heavy environment.
So, why isn’t that the answer? Why shouldn’t you just constantly add heavy indexes to a read-only table? Because, as ever with databases, there is always something else to consider.
The 4 dimensions of database indexing
Even with writes out of the picture, there are factors that determine the efficiency of indexing: table size, query type, data format, and resource constraints.
Table size
TL;DR: For small tables, full table scans can be as efficient or even more efficient than using an index. Postgres can load small tables into memory, making sequential scans very fast.
This is the first dimension we need to consider. In the Reddit example above, the table had about 8k rows. At this size, an index will provide negligible performance gains – Postgres can scan that very efficiently.
Let’s prove it: we’ll create the products table above and populate it with 10k rows of data. The dable structure looks like this:
CREATE TABLE IF NOT EXISTS products (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
category VARCHAR(50),
price DECIMAL(10, 2),
stock_quantity INTEGER,
manufacturer VARCHAR(100),
created_at TIMESTAMP
);
We’ll then run a simple query with and without a simple index:
SELECT * FROM products WHERE category = 'Electronics';To support this query, we will create an index on the category column:
CREATE INDEX idx_category ON products(category);The execution times:
- Without index: 0.0002
- With index: 0.0002
The same. There might be a few nanoseconds in it, but you are getting the same performance with or without the index at this table size.
Why? The database can often load the entire table into memory at small table sizes, allowing for rapid full table scans that are just as efficient as (or sometimes even faster than) index lookups. Index lookups involve additional I/O overhead to read the index structure and then fetch the corresponding data pages.
Query type
TL;DR: For larger tables and simple queries that touch a significant portion of the table, indexes can slow things down. For complex queries involving multiple conditions, indexes can significantly improve performance.
Now, let’s try the same simple query but with 10M rows:
- Without index: 0.0026 s
- With index: 0.0078 s
Wait, what? This might initially seem counterintuitive, but it’s not uncommon, especially for more straightforward queries on moderately sized tables. Let’s break down why this might be happening:
- When we use an index, the database first has to traverse the index structure to find the relevant rows and then fetch those rows from the table. For a small number of rows, this two-step process can be slower than just scanning the entire table.
- Table scans are sequential read operations, so they are generally faster than the random I/O required for index lookups, especially on traditional hard drives. Even with SSDs, sequential reads can be more efficient for a specific range of data sizes.
- If our query is returning a large percentage of the rows (low selectivity), a full table scan might be more efficient. The optimizer might choose the index scan expecting better selectivity, but if it ends up touching a large portion of the table anyway, it could be slower than a direct table scan.
But what happens when we start dealing with more complex queries? The initial question was about using this table for a search page. Let’s consider what that might entail. A typical search might involve multiple conditions, perhaps something like this:
SELECT * FROM products
WHERE category = 'Electronics'
AND price BETWEEN 100 AND 500
AND manufacturer = 'TechCorp'
AND stock_quantity > 0
ORDER BY price DESC
LIMIT 20;This query is a whole different ballgame compared to our simple single-column lookups. It involves multiple conditions, a range query, sorting, and a limit. Let’s see how this performs on our 10 million row table:
- Without index: 20.7916 s
- With index: 3.3972 s
Now we’re cooking on indexes. This complex query demonstrates where indexing starts to shine. Let’s break down why:
- Multiple conditions: Our query filters on category, price, manufacturer, and stock_quantity. A composite index on these columns can significantly speed up the WHERE clause evaluation.
- Range query: The BETWEEN condition on price benefits from an index, allowing the database to quickly narrow the range without scanning all rows.
- Sorting: The ORDER BY clause on price is accelerated by an index, avoiding a potentially expensive sort operation.
- LIMIT clause: With an appropriate index, the database can stop scanning once it finds the top 20 rows rather than sorting the entire result set.
This is really the key point for choosing indexes. Databases exist to serve data when queried. Any optimizations, such as indexes, need to support this mission. Therefore, if you have complex queries, you should add indexes to the columns that appear frequently in your WHERE clauses, JOIN conditions, ORDER BY statements, and GROUP BY clauses. These indexes should be designed to support your most critical and resource-intensive queries, balancing query performance with the overhead of maintaining multiple indexes.
Data format
TL;DR: High cardinality and easily orderable data types work best.
Data format is less of an issue, but it is still something to consider when creating indexes in Postgres.
Postgres, like most database systems, primarily uses B-tree structures for its indexes. B-trees are designed to maintain sorted data and allow for efficient searches, insertions, and deletions. They work by organizing data into a tree-like structure where each node contains multiple key-value pairs and pointers to child nodes. This structure allows for quick traversal to find specific values or ranges. B-trees are most effective when their indexing data can be meaningfully sorted. For instance, numbers and dates have a clear, natural ordering that B-trees can leverage.
In the original Reddit post, the user mentioned having 20 boolean columns. Boolean values, with only two possible states, have very low cardinality, so they don’t provide much opportunity for the B-tree to optimize searches. Similarly, long text fields or complex data types can be challenging for B-trees to organize efficiently, potentially leading to slower performance or larger index sizes.
Resource constraints
TL;DR: Remember that indexing heavily might affect your resource consumption.
Finally, your tables exist on disks and in memory and are accessed by CPU and I/O. These physical realities play a crucial role in your indexing strategy. Let’s break it down:
- Every index you create takes up additional disk space. For small tables, this might not be a big deal. But when you’re dealing with millions of rows, indexes can significantly increase your storage requirements.
- Postgres, like most databases, benefits from having frequently accessed data and index pages in memory for faster access. More indexes mean more memory pressure. If your indexes don’t fit in RAM, you’ll see increased I/O as the database constantly swaps data between memory and disk.
- Indexes can dramatically reduce the number of I/O operations for reads but increase I/O for writes. Every time you insert, update, or delete a row, all affected indexes must also be updated. On a write-heavy system, too many indexes can become a performance bottleneck.
- While often overlooked, index maintenance and traversal consume CPU cycles. Complex indexes or too many indexes can increase CPU load, especially during write operations or when the query optimizer is figuring out which index to use.
So, going back to the Reddit example with their 20 boolean columns: Boolean columns are small, so indexing all 20 might not be a huge storage hit. With only 8k rows, the entire table (and probably all indexes) can easily fit in memory on most modern systems. Since updates are rare and admin-only, the write performance hit from multiple indexes is probably acceptable.
The takeaway
Indexing strategies in Postgres are all about balance, even when ingest performance is not important. Like we said… It depends!
For small tables of a few thousand rows, full table scans can be as efficient as using an index, so you might not gain anything by indexing heavily; as table size grows, indexes become more beneficial, especially for complex queries involving multiple conditions. High cardinality and easily orderable data types typically work best for indexing. Again, don’t forget that indexes require resources.